By
By 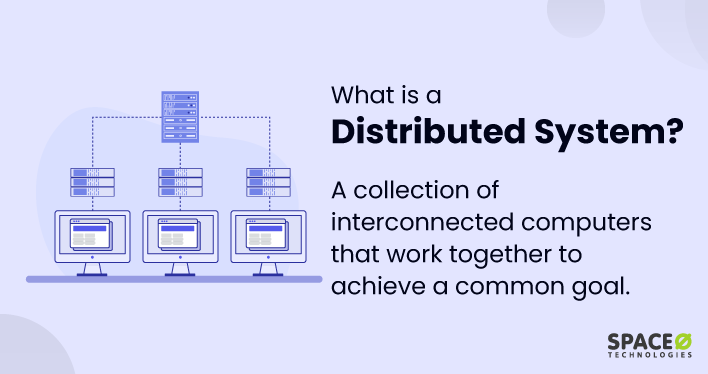
Table of Contents
What is a Distributed System?
A distributed system is a collection of interconnected computers, servers, or devices that work together as a single, cohesive unit to achieve a common goal.
In this type of system, components communicate and share resources with one another to function efficiently and effectively. They can be located in close proximity, such as within a single building, or spread across vast distances, connecting over the internet.
Why Distributed System is Important?
Distributed systems are important because they offer several advantages over centralized systems, making them well-suited for a wide range of applications and use cases. The advantages of distributed computing include:
Adapts to the Increase Workloads and User Demands
Distributed systems handle growing workloads and increasing user demands by adding more resources, such as servers or processing power. This horizontal scaling capability allows the system to manage a larger number of requests while maintaining performance. Scalability enables to accommodate rapid growth and fluctuations in demand without compromising user experience.
Ensures System Continuity in the Face of Failures
In a distributed system, if one component or node fails, the rest of the system can continue functioning without significant disruption. By incorporating redundancy and replication strategies, distributed systems minimize the impact of system failures on overall performance and availability. This resilience in distributed computing ensures that critical applications remain operational, even if the hardware fails, single computer network outages, or other unforeseen issues.
Boosts Performance and Utilization through Collaboration
Distributed systems enable the efficient sharing of resources, such as processing power, storage, and communication network bandwidth. This leads to improved performance and resource utilization, as components work together to complete tasks quickly. In distributed computing, resource sharing is beneficial in large-scale applications, where resource management is key to maintaining performance and reducing costs.
Enhances User Experience with Geographically Distributed Systems
In geographically distributed systems, components are strategically located closer to end-users, which reduces the time it takes for data to travel between the user and the system. Distributed computing reduces latency translates to faster response times and a better overall user experience. Geographical distribution is valuable for content delivery networks (CDNs), online gaming platforms, and other applications where low latency is crucial for user satisfaction.
Maintains System Performance During High Demand Periods
Load balancing is the process of distributing workloads evenly among multiple components or nodes within a distributed system. This distributed architecture ensures that no single component becomes overloaded with requests, helping to maintain system performance even during high demand. Effective load balancing techniques, such as round-robin, least connections, or adaptive algorithms, are preventing bottlenecks that reduce response times, and ensure that applications remain responsive and reliable.
What are the Types of Distributed Systems?
There are several types of distributed system architecture, each with its own characteristics and use cases. Here are some common types of distributed systems:
- Cluster Computing Systems: Cluster computing systems consist of interconnected multiple machines, often located in close proximity, that work together to perform tasks as a single unit. These systems provide high availability, fault tolerance, and load balancing. They are often used for high-performance computing, scientific simulations, and data processing tasks.
- Grid Computing Systems: Grid computing systems are large-scale distributed systems that involve sharing computational resources across multiple organizations. These systems enable users to access and utilize idle resources from other computer systems in the grid, optimizing resource usage. Grid computing is often used for solving complex computational problems or for collaborative projects that require significant computing power.
- Cloud Computing Systems: Cloud computing systems are a type of distributed system where computing resources, such as storage, processing power, and databases, are provided as a service over the internet. Users can access and manage these resources remotely, enabling on-demand scalability, cost savings, and flexibility. Cloud computing encompasses various service models, including Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS).
- Content Delivery Networks (CDNs):
CDNs are networks of geographically distributed servers that store and distribute content, such as web pages, multimedia files, and software updates. CDNs reduce network latency and improve user experience by serving content from a server located close to the user. They also help balance server load and ensure content availability during high-traffic periods or server failures.
By applying the principles of fault tolerance, these distributed systems deliver reliable, efficient, and continuous service, minimizing disruptions and ensuring high availability. If you want more ideas on fault tolerance, here is a brief explanation of fault tolerance. Reading this post, you will know about the best techniques and benefits of a fault-tolerant system. You will better understand the crucial role it plays in the operation of these distributed systems.
7 Best Practices for Monitoring and Managing Distributed Systems
Monitoring and managing distributed systems effectively is crucial for ensuring optimal performance, and resource utilization.
Here are the 7 best practices to follow:
- Implement Centralized Monitoring: Use a centralized monitoring tool or platform that can collect, analyze, and visualize data from all components of your distributed system. This will provide a comprehensive, real-time view of the system’s health, performance, and resource usage and help to overcome the challenges of distributed systems.
- Monitor Key Performance Metrics: Track important performance metrics, such as response times, throughput, error rates, and resource utilization, to detect potential. Set up alerts to notify you of anomalies or threshold breaches.
- Monitor Component Availability: Regularly check the availability of each component in the system to detect failures or connectivity issues. Implement automated health checks and use heartbeat mechanisms to ensure that components are functioning correctly.
- Collect and Analyze Logs: Aggregate and analyze log data from all components to gain insights into system behavior, detect errors, and troubleshoot issues. Use log management tools to filter, search, and visualize log data effectively.
- Implement Distributed Tracing: Distributed tracing enables you to track requests as they propagate through the system, providing end-to-end visibility into the performance and latency of individual components and services. Use distributed tracing tools to identify bottlenecks, optimize request paths, and troubleshoot issues.
- Automate Incident Management: Set up an automated incident management process that notifies the appropriate team members of issues, creates tickets, and tracks resolution progress. This will help ensure that incidents are addressed quickly and efficiently.
- Maintain Configuration Consistency: Ensure that configurations for all components in the distributed system are consistent and up-to-date. Use configuration management tools and version control systems to manage and track configuration changes.
Distributed computing offers significant advantages in scalability, fault tolerance, and resource utilization, making distributed computing systems and applications essential for various modern use cases. By understanding the different types of distributed systems and using best practices for monitoring and managing these systems, you can harness their full potential and create robust, high-performance distributed applications.